A couple of months ago, Brett Cannon, one of the better known Python core developers, announced on Twitter that he contributed to over 100 open source projects.
first reaction
Woohah! Congratulations!
second reaction
How did he know?
Every time I get a PR merged I record the repo’s URL for a tool I created to analyze my contributions to OSS.
Ah… k. I did not do that.
third reaction
To how many open source projects did I contribute?
Well, I only started contributing recently, like one year ago or so…
and as I said, I did not take any notes…
but “luckily” nowadays like most open source development happens on Github.
As far as I remember I only contributed to a couple projects which are not present on GitHub,
and that was for batou and Roundcube (as of 2021, both are now also on GitHub).
So, if only GitHub provided some API to query the data it stored about me… well, it does.
say hello to graphql
GraphQL is a query language for web APIs. It was developed by Facebook, and according to rumors it will supersede REST in the near future.
GitHub kindly not only offers an API, but also an in-browser IDE (based on GraphiQL) to explore the data.
say hello to graphiql
When you first hit GitHub’s instance of GraphiQL ( https://developer.github.com/v4/explorer/ ), you will see something like this:
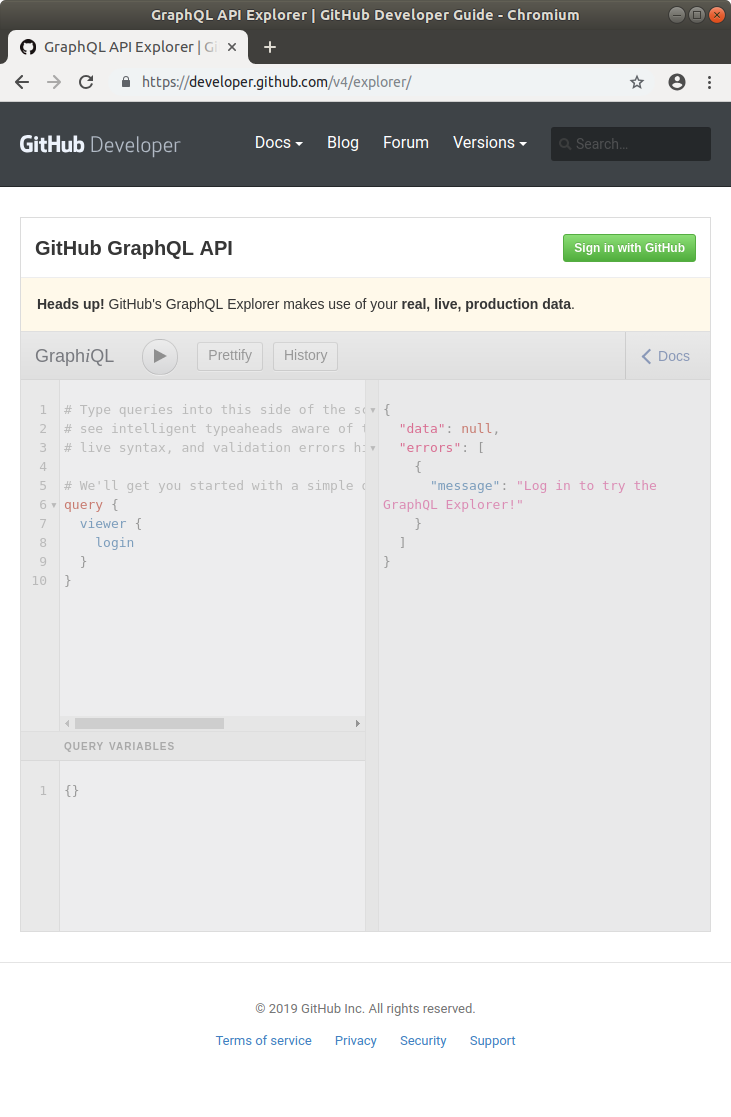
So, obviously, first you have to login with your Github credentials (green “Sign in with GitHub” button in the top right).
first encounter
When I first saw this page, I played around a bit and left - as I did not get what I wanted. Luckily, at last weekend’s PyConWeb19, Arthur Bayr did a workshop on GraphQL and Graphene - thanks a ton!
Now I am ready to explore my data!
overview
On the top left, there is room to enter the query.
On the right, the result will be shown.
On the far right, there is the small, but super helpful Docs button.
On the bottom left is something I did not use yet.
iteration one
After you have logged in, leave the query as is…
query {
viewer {
login
}
}
… and just hit the play button above the “query field”.
You should get a result similar to mine - but with your username.
{
"data": {
"viewer": {
"login": "jugmac00"
}
}
}
explanation
- query outside the curly braces is just a name
- viewer is a data type, and it happens to be the currently authenticated in user
- login is a subfield of viewer
How do I know this?
On the far right, there is the Docs button. Small button, but lots and lots of information! Actually, you can explore the complete API when you open the docs and follow the links.
iteration two
Either by reading the docs or by hitting CTRL+SPACE which triggers autocompletion when you are in the query box, you will eventually come across a subfield with name repositoriesContributedTo - that sounds fine!
Note:
You cannot query arbitrary data - all fields, subfields, parameters… have to be defined by the API provider.
When you just enter the following…
query {
viewer {
repositoriesContributedTo
}
}
… right below repostoriesContributedTo there will be a red squiggly line. When you hover over the word, you can read “Field .. must have a selection of subfields”.
Whatever! The cool thing… if you hit the play button anyway, the IDE autocompletes your query to…
query {
viewer {
repositoriesContributedTo {
edges {
node {
id
}
}
}
}
}
The result is… hm… an error message:
“You must provide a first or last value to properly paginate the repositoriesContributedTo connection.”
Ok, let’s do this.
iteration three
Generally speaking, it is a very good idea to force pagination on all APIs, which return lists - another thing I learned at PyConWeb19 - no slides, but there is a video from another conference: Tech bankruptcy: Looking back on a decade of bad decision making
The mentioned value is actually a parameter, and parameters are put into parenthesis behind a (sub)field name, just like…
query {
viewer {
repositoriesContributedTo(first: 100) {
edges {
node {
id
}
}
}
}
}
If you only type first, you get a friendly reminder to provide a number, which must not be greater than 100.
The result…
{
"data": {
"viewer": {
"repositoriesContributedTo": {
"edges": [
{
"node": {
"id": "MDEwOlJlcG9zaXRvcnk2OTI2NTQ="
}
},
...
… does not look to bad, but not very human readable.
iteration four
If you replace id with nameWithOwner (via API exploration STRG+SPACE or from the docs), you’ll get much better data:
query {
viewer {
repositoriesContributedTo(first: 100) {
edges {
node {
nameWithOwner
}
}
}
}
}
The result…
{
"data": {
"viewer": {
"repositoriesContributedTo": {
"edges": [
{
"node": {
"nameWithOwner": "python-babel/flask-babel"
}
},
{
"node": {
"nameWithOwner": "malthe/chameleon"
}
},
...
But we want the total number of contributions.
iteration five
As I learned at the workshop, either the server or the client has to implement some count or sum functions, as you can only query what is offered (or process it client side).
So, let’s have another look, what repositoriesContributedTo has to offer…
If you click on repositoriesContributedTo and then on RepositoryConnection! in the Docs, you’ll see totalCount - nice! And also, you’ll see nodes, which can simplify the “first get all edges and then the corresponding nodes” syntax.
query {
viewer {
repositoriesContributedTo(first: 100) {
totalCount
nodes {
nameWithOwner
}
}
}
}
The result…
{
"data": {
"viewer": {
"repositoriesContributedTo": {
"totalCount": 66,
"nodes": [
{
"nameWithOwner": "python-babel/flask-babel"
},
{
"nameWithOwner": "malthe/chameleon"
},
...
Very nice… except… also proprietary (private) repositories are listed…
iteration six
Visiting the docs again, repositoriesContributedTo offers a privacy parameter.
query {
viewer {
repositoriesContributedTo(first: 100, privacy: PUBLIC) {
totalCount
nodes {
nameWithOwner
}
}
}
}
The final result…
{
"data": {
"viewer": {
"repositoriesContributedTo": {
"totalCount": 54,
"nodes": [
{
"nameWithOwner": "python-babel/flask-babel"
},
{
"nameWithOwner": "malthe/chameleon"
},
...
what’s left
First, once again, thank you very much Arthur for teaching me the basics of GraphQL!
Now it is up to the reader to explore the API further… oh wait… what is the includeUserRepositories parameter doing…
Damn! I missed to include my very own projects! :-)
notes
I presented this topic as a lightning talk at Mobile Stammtisch/GDG Regensburg on 12. December 2019.
updates
2019-12-28
- add notes about lightning talk